K-means Clustering: Understanding Algorithm with animation and code
Overview of Mathematical and geometrical intuition of K-Means clustering algorithm with Python code.

Unsupervised Learning is a type of machine learning process which tries to find unexplored trends in data points without the help of the pre-defined labeled data and in minimalist human intervention. It works on the dataset without target variables. Clustering and Anomaly detection are the two major types of unsupervised learning.
‘’In unsupervised learning, guide is absent, and the algorithm learns to sense the data without any assistance.’’
Clustering is the unsupervised learning process of dividing data points into groups such that data points belonging to the same groups have similar features to other data points in the same group and are dissimilar to the data points belonging to different groups.

Clustering is based on two important metrics i.e Inter-Cluster distance and Intra-cluster distance. In ideal conditions for clustering to perform well the inter-cluster distance should be very high and intra-cluster distance should be very low. Based on these two distances we can measure the performance of clustering techniques using the Dunn index. If the Dunn index is high it states that the clustering is done with higher accuracy.

Geometric intuition of K-Means

K-Means is the most popular centroid-based clustering algorithm. This algorithm takes the data points and gives the predefined set of clusters. Consider dataset D={x1,x2……,xn} has n points with k clusters(S1,S2..Sk) and each cluster assigned with one centroid( C1,C2, C3..Ck). Every point in the dataset is assigned to the set (Si) depending on the nearest centroid to it. The centroid(Ci) is the mean point to all the other points in the given set of points (Si). It is calculated as below:
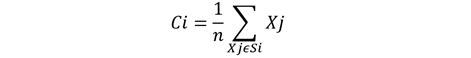
Mathematical Formulation of K-means
The main objective of the K- means algorithm is to find k centroids and assign each point to set Si based on the nearest centroid Ci such that the intra-cluster distance is minimized. The optimal centroids are found by taking the sum of squares of distances of points from its centroid. The optimization problem here is defined as:
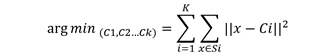
This optimization problem is an NP-hard problem which makes it difficult to exactly solve this problem so we choose to solve this problem with approximation using Lloyds Algorithm.
Lloyd’s Algorithm
We are given dataset D of n points {X1,X2…Xn} and we have to find K centroids. We follow below steps to implement Llyods algorithm.

Step 1- Initialization stage
a) Randomly pick k points from the dataset and initialize them as k centroids.

Step 2-Assignment stage
For each point Xi in D:
a) Select the nearest centroid Cj by finding distance between point Xi and centroid Cj for all the k clusters

b) Add Xi to set Sj corresponding to centroid Cj.
Here in this step all n points are assigned to only one set Sj where j=1,2,..k.

Step 3- Recalculate stage
a) Take all the points in the set Sj and find the mean point and update it as the new centroid.
In this step the old centroids are updated using below formula:
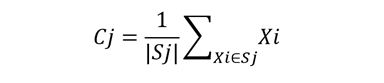

Step 4
Repeat step 2 and step 3 till convergence (The state where there is a very small update in the new centroids over the old centroids).


Determining the right number of Clusters
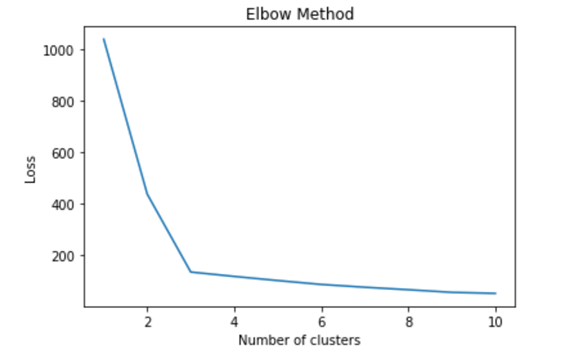
Firstly we can know from domain knowledge what should be the number of clusters for eg, When we are going to group the Twitter tweets based on their sentiments then we know that sentiment will be either positive, negative, or neutral. Secondly, the basic idea behind the objective/loss function of K-Means clustering is to minimize the total sum of the intracluster distances by finding the optimal centroids. We plot the loss function on the y-axis across the different values of K by randomly initializing the K-Means algorithm. The resulting graph looks like the structure of the elbow, therefore this method is called as Elbow method.
Limitations of K-Means
- With different initialization of centroids, we get different clusters at the end of the clustering.

2. K-means can give the clusters different sizes than the actual data points. It also gives clusters with different densities.
3. K-means does not give proper results when applied to the nonconvex shapes.

4.K-means is prone to outliers and does not give good results when the outliers are present.
Code snippet for K-means
Import all the packages which are required for K-means. There is separate module in sklearn for K-means.
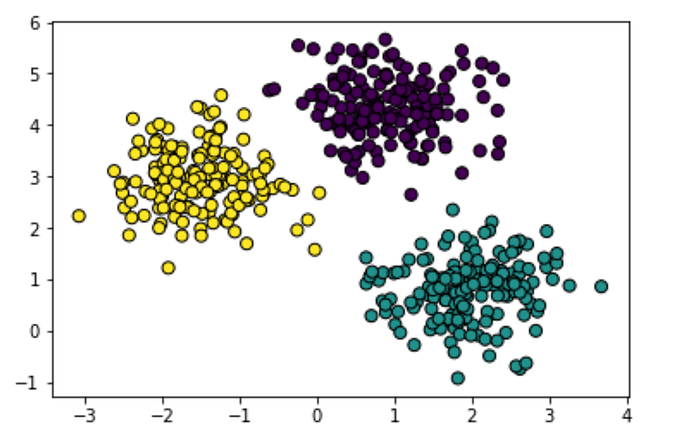
Let’s plot the dataset and check for the placement of clusters.
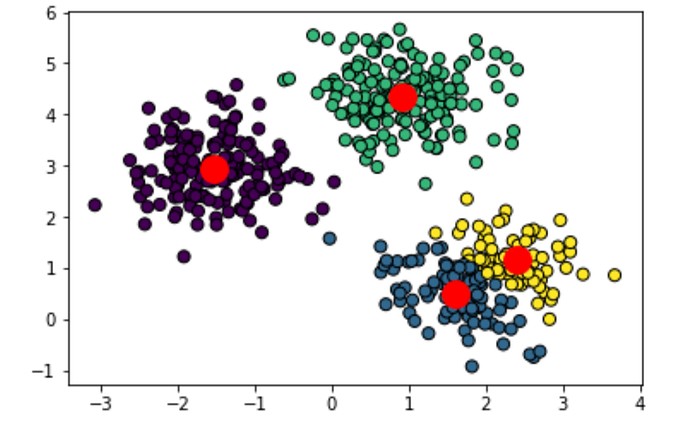
Building the K-Means model
For any doubts, you can comment below and I will get back to you. If you find this blog useful please share and give a clap.:)
